Vibe Coding
Kills Factory Software
AI builds factory software that looks production-ready. It isn't. Karpathy-style prompts make it safe to ship.
4 Troubling Results
In a factory, steel mill, hospital, or any consequential use case, these 4 gaps are big problems. The research shows where they appear and how to fix them.
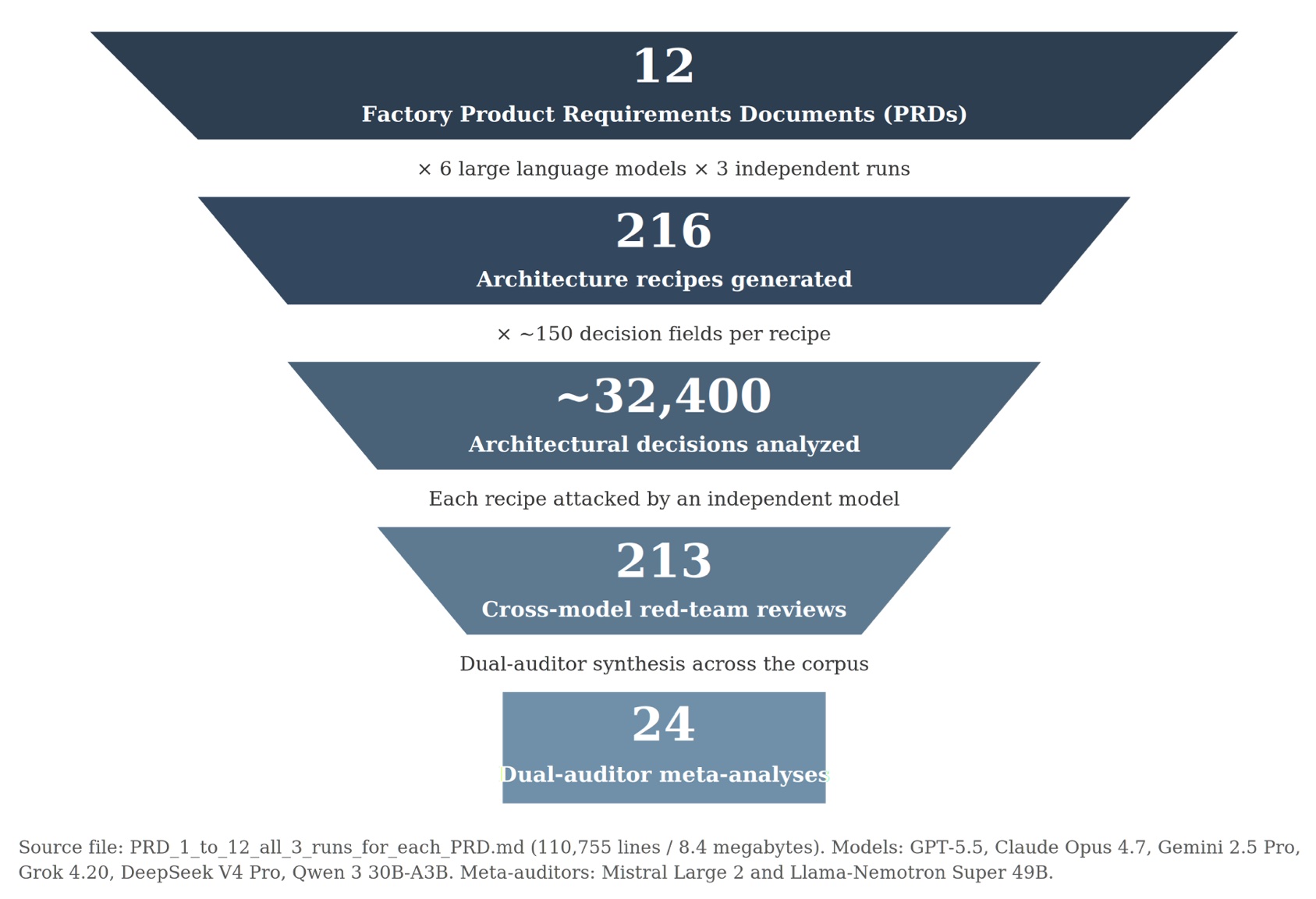
12 PRDs × 6 LLMs × 3 runs • 32,400 architectural decisions • 213 red-team reviews
Who this is for
The doctrine was built for software whose failures have real-world consequences. It will be most useful if you recognize yourself below.
- You ship code that ends up running factories, refineries, hospitals, plants, or power grids.
- Your architecture has to pass a safety review — not just a code review.
- You use AI assistants and worry, correctly, about what they're quietly skipping.
- You're a cybersecurity lead, safety engineer, auditor, or regulator trying to make AI-assisted design accountable.
- You build consumer apps where bugs are inconvenient, not dangerous.
- You're already convinced AI doesn't need guardrails in safety-critical work.
- You're looking for generic prompt-engineering tips — this is empirical doctrine, not advice.
- You want a how-to-build-with-AI tutorial.
The Research — The Paper at a Glance
In a controlled study, six leading AI models (GPT-5.5, Claude Opus 4.7, Gemini 2.5 Pro, Grok 4.20, DeepSeek V4 Pro, and Qwen 3 30B-A3B) were given the same factory automation requirements that a real engineering team would use. They produced 216 detailed architecture recipes.The results were troubling:
- Zero recipes included the formal safety engineering — HAZOP (Hazard and Operability study), LOPA (Layer of Protection Analysis), and SIL (Safety Integrity Level) — that was required in the written specification.
- 79% added cloud dependencies despite clear requirements for fully offline systems.
- One model weakened required cybersecurity standards in 89% of its outputs.
This research introduces ten practical guardrails and acceptance gates, along with ready-to-use copy-paste prompts, to make AI-assisted architecture reliable in high-consequence environments.
216 architecture recipes • 6 frontier LLMs • 3 runs each • 213 red-team reviews
HAZOP Hazard and Operability study · LOPA Layer of Protection Analysis · SIL Safety Integrity Level
Plausibility Is Not Readiness
The models spoke the language of industrial automation while quietly skipping the actual engineering work that keeps factories safe, cyber-secure, and reliable.
The 12 Factory PRDs
All six models received the same twelve product requirements documents. Each describes a real factory problem.
- Receiving Quality & Supplier Scorecards. Automatically inspect incoming materials, accept or reject batches, and track supplier reliability.
- Machine Downtime Tracking & Andon. Detect unexpected machine stops, alert the right people, and record causes for improvement.
- Energy Consumption Monitoring. Measure electricity and compressed-air usage so the factory can reduce waste and cost.
- Predictive Maintenance for Critical Equipment. Use sensor data to predict failures before machines break down during production.
- Part Genealogy & Traceability. Record each part’s manufacturing history so defects can be traced quickly.
- In-Process Quality Inspection. Check part quality during production instead of waiting until the end.
- Work-in-Process (WIP) Tracking. Know where every batch or part is located inside the factory.
- Overall Equipment Effectiveness (OEE) Dashboard. Show managers and operators how efficiently equipment is running.
- Brownfield Legacy PLC & SCADA Integration. Connect new software to old control systems without replacing everything.
- Electronic Batch Records for Compliance. Create digital records that satisfy auditors in regulated production environments.
- Chemical Blending Process Control. Control chemical mixing according to recipes while meeting safety and quality rules.
- Aerospace Precision Machining Data Collection. Capture precise machine data for quality reporting and regulatory compliance.
The Ten Industrial AI Guardrails
Each guardrail is a Karpathy-upgraded copy-paste prompt reverse-engineered from a repeatable failure pattern in the 216-recipe corpus. Click View full prompt to read it, download as .md, or copy to clipboard.
Never Accept a proposed Software Architecture That Skips Formal Safety Analysis
Zero of 216 recipes performed HAZOP, LOPA, or SIL — even on safety-critical equipment.
Never Use Small Open-Weights Models Without Heavy Review
Qwen downgraded security in 89% of outputs and produced 73% of all hallucinations.
Never Permit Cloud-Component Creep
171 of 216 recipes added cloud dependencies despite explicit offline requirements.
Treat PostgreSQL Consensus as a Hypothesis, Not Gospel
PostgreSQL + TimescaleDB appeared in 215/216 recipes. Strong consensus ≠ correctness.
Mandate Edge-First, On-Premises Simplicity Unless Proven Otherwise
Complex distributed systems were repeatedly proposed for small factories with one IT person.
Standardize Identity, Encryption, and Network Segmentation
Models used vague “secure by design” language without enforceable controls.
Require a Truly Offline-Capable Frontend
Modern PWAs often failed basic shop-floor outage and glove-use tests.
Use an Independent Seventh LLM for Red-Team Review
The generator cannot reliably attack its own assumptions and blind spots.
Account for Stable Model Personality
Each LLM showed consistent, reproducible biases across all 12 PRDs and 3 runs.
Never Trust Self-Assessed Scores
Higher confidence scores often predicted more external criticism, not higher quality.
All prompts are also available in the repository under /prompts/